Kafka是一个分布式的,支持多分区、多副本,基于Zookeeper的分布式消息流平台,同时也是一款开源的基于发布订阅模式的消息引擎系统
基本术语
消息:kafka中是数据单元被称为消息,也被称为记录,可以把它看做数据库表中某一行记录
批次:为了提高效率,消息会分批次写入kafka,批次就代指一组消息
主题:消息的种类称为主题, 可以说一个主题代表了一类信息,相当于是对消息进行了分类,主题就像是数据库中的表
分区:主题可以被分为若干个分区(partition),同一个主题中的分区可以不在一个机器上,有可能会部署在多个机器上,由此来实现 kafka 的伸缩性,单一主题中的分区有序,但是无法保证主题中所有的分区有序
偏移量:偏移量是一种元数据,它是一个不断递增的整数值,用来记录消费者发生重平衡时的位置,以便用来恢复数据。
重平衡:消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
broker: 一个独立的 Kafka 服务器就被称为 broker,broker 接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。
消费者****群组:指的是由一个或多个消费者组成的群体
kafka特性
**高吞吐、**低延迟:kakfa 最大的特点就是收发消息非常快,kafka 每秒可以处理几十万条消息,它的最低延迟只有几毫秒。
高伸缩性:每个主题(topic) 包含多个分区(partition),主题中的分区可以分布在不同的主机(broker)中。
持久性、可靠性:Kafka 能够允许数据的持久化存储,消息被持久化到磁盘,并支持数据备份防止数据丢失,Kafka 底层的数据存储是基于 Zookeeper 存储的
容错性:允许集群中的节点失败,某个节点宕机,Kafka 集群能够正常工作
高并发:支持数千个客户端同时读写
使用场景
活动跟踪:Kafka 可以用来跟踪用户行为,比如我们经常回去淘宝购物,你打开淘宝的那一刻,你的登陆信息,登陆次数都会作为消息传输到 Kafka ,当你浏览购物的时候,你的浏览信息,你的搜索指数,你的购物爱好都会作为一个个消息传递给 Kafka ,这样就可以生成报告,可以做智能推荐,购买喜好等。
传递消息:Kafka 另外一个基本用途是传递消息,应用程序向用户发送通知就是通过传递消息来实现的,这些应用组件可以生成消息,而不需要关心消息的格式,也不需要关心消息是如何发送的。
度量指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
日志记录:Kafka 的基本概念来源于提交日志,比如我们可以把数据库的更新发送到 Kafka 上,用来记录数据库的更新时间,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
流式处理:流式处理是有一个能够提供多种应用程序的领域。
限流削峰:Kafka 多用于互联网领域某一时刻请求特别多的情况下,可以把请求写入Kafka 中,避免直接请求后端程序导致服务崩溃。
kafka系统架构
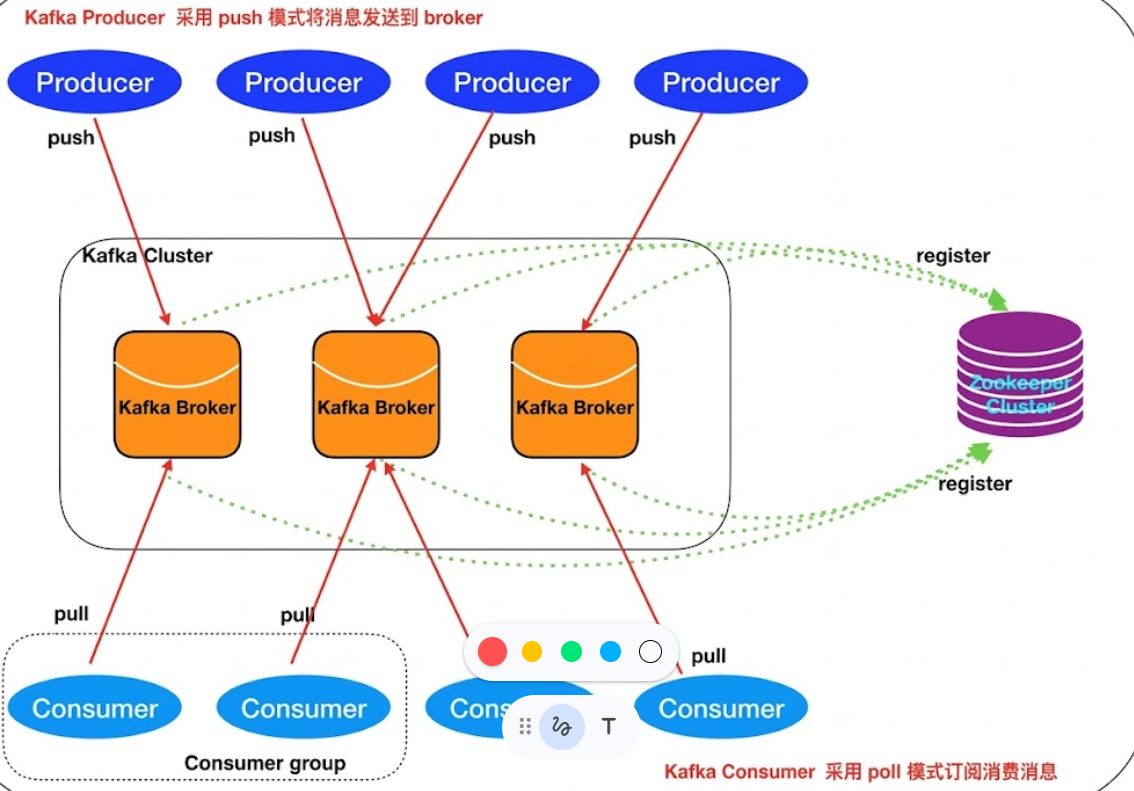
一个典型的 Kafka 集群中包含若干Producer(可以是web前端产生的Page View,或者是服务器日志,系统CPU、Memory等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
Kafka特点
顺序写入
Kafka 将消息持久化到磁盘时,采用的是只追加 (Append-Only) 的模式。这种顺序写入的方式避免了磁盘磁头频繁寻道(随机写入)的巨大开销,
零拷贝
在传统的数据传输中(从磁盘读取并发送到网络),数据需要在内核空间和用户空间之间多次拷贝,消耗大量 CPU 和内存资源。
kafka利用linux的sendfile()系统调用,数据直接从磁盘传输到网卡,完全绕过来用户空间,减少了两次数据拷贝和上下文切换,显著提升了数据传输效率
批处理
无论是生产者发送还是消费者拉取,Kafka 都以“批”为单位进行。
- 生产者:不会每产生一条消息就立即发送,而是先在本地攒成一个批次(例如,攒够 16KB 或等待 5ms),然后一次性发送。
- 消费者:也是一次性拉取一批消息,而不是一条一条地获取。
消息压缩
Kafka 支持对批量消息进行压缩(如 Snappy, LZ4, GZIP 等)。由于批量消息的数据量大且有重复性,压缩率非常高(例如 JSON 消息可达 80%)。压缩后的数据在网络上传输和磁盘上存储时,体积大幅减小,进一步提升了网络 I/O 和磁盘 I/O 的效率。
消费者组优势
消费者组解决的是分布式下的分区分配、位移和容错,多进程消费通常需要自己分区,且偏移量需要自己记录,否则重启容易重复消费或丢进度。
消费者组由Kafka在broker侧维护组内有哪些成员,消费者会向broker发送心跳来维护自己是消费者组的一员。组内每个消费者实例拿到一部分分区,但一个分区同一时刻在组内只应被一个消费者处理。成员上下线会rebalance,分区在存活成员间自动重分。偏移量按group.id+topic+partition提交到集群,别的示例接管分区后可以从上次提交继续
Kafka使用
在Go语言中操作Kafka主流的客户端有两个:
- Sarama:纯Go实现,无第三方依赖
- confluent-kafka-go:基于c语言 librdkafka,性能高
安装依赖
1
| go get github.com/IBM/sarama
|
通用配置
1
2
3
4
5
6
7
8
9
10
| import (
"github.com/IBM/sarama"
)
func newConfig() *sarama.Config {
cfg := sarama.NewConfig()
cfg.Version = sarama.V3_6_0_0
cfg.Producer.Return.Successes = true
cfg.Consumer.Return.Errors = true
return cfg
}
|
Version:Kafka协议版本Producer.Return.Successes:Producer是否需要确认消息发送成功Consumer.Return.Errors:是否需要自动将错误推送到Errors通道
同步生产者
适合需要确认发送结果的场景(如订单消息),SendMessage发送后会阻塞等待Kafka响应,发完一条消息需要等待后才能再发一条。创建主题时建议使用比较多的分区数,这样可以在消费负载高的情况下增加消费者来提升性能。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
func runProducer(brokers []string, topic string) error {
cfg := newConfig()
p, err := sarama.NewSyncProducer(brokers, cfg)
if err != nil {
return fmt.Errorf("创建生产者: %w", err)
}
defer func() { _ = p.Close() }()
for i := 0; i < 5; i++ {
key := fmt.Sprintf("user-%d", i%3)
body := fmt.Sprintf("msg-%d-%s", i, time.Now().Format(time.RFC3339Nano))
msg := &sarama.ProducerMessage{
Topic: topic,
Key: sarama.StringEncoder(key),
Value: sarama.StringEncoder(body),
}
partition, offset, err := p.SendMessage(msg)
if err != nil {
return fmt.Errorf("发送失败: %w", err)
}
}
return nil
}
|
异步生产者
异步生产者适合海量消息,不阻塞的场景,性能远高于同步生产者,通过Input()投递,结果在Successes()和Errors()中获取
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| func runProducerAsync(brokers []string, topic string) error {
cfg := newConfig()
p, err := sarama.NewAsyncProducer(brokers, cfg)
if err != nil {
return fmt.Errorf("创建 AsyncProducer: %w", err)
}
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
for msg := range p.Successes() {
log.Printf("发送成功:",mshg)
}
}()
go func() {
defer wg.Done()
for pe := range p.Errors() {
log.Printf("发送失败 %v", pe.Err)
}
}()
for i := 0; i < 5; i++ {
key := fmt.Sprintf("user-%d", i%3)
body := fmt.Sprintf("async-%d-%s", i, time.Now().Format(time.RFC3339Nano))
p.Input() <- &sarama.ProducerMessage{
Topic: topic,
Key: sarama.StringEncoder(key),
Value: sarama.StringEncoder(body),
}
}
if err := p.Close(); err != nil {
return fmt.Errorf("关闭 AsyncProducer: %w", err)
}
wg.Wait()
return nil
}
|
消费者
Kafka只需写入一次消息,可以支持多个应用读取该消息,每个应用都可以读到全量的消息,消费者的数量不应该比分区数多,因为多出来的消费者是空闲的,没有任何帮助。
c.ConsumePartition 启动该 topic 的 partition 的消费者
并返回对应的 PartitionConsumer(pc),用于读取该分区的消息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| func runConsumerAll(brokers []string, topic string) error {
cfg := newConfig()
c, err := sarama.NewConsumer(brokers, cfg)
if err != nil {
return fmt.Errorf("创建消费者: %w", err)
}
defer func() { _ = c.Close() }()
parts, err := c.Partitions(topic)
if err != nil {
return fmt.Errorf("查询分区: %w", err)
}
if len(parts) == 0 {
return fmt.Errorf("topic %q 无分区或不存在", topic)
}
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
var wg sync.WaitGroup
for _, p := range parts {
wg.Add(1)
go func(partition int32) {
defer wg.Done()
pc, err := c.ConsumePartition(topic, partition, sarama.OffsetNewest)
if err != nil {
log.Printf("分区 %d 启动失败: %v", partition, err)
return
}
defer func() { _ = pc.Close() }()
for {
select {
case <-ctx.Done():
return
case err := <-pc.Errors():
if err != nil {
log.Printf("分区 %d 错误: %v", partition, err)
}
case msg, ok := <-pc.Messages():
if !ok {
return
}
log.Printf("接收消息:",msg)
}
}
}(p)
}
wg.Wait()
return nil
}
|
消费者组
消费者组处理器必须实现 sarama.ConsumerGroupHandler 接口,group.Consume启动消费者组消费流程,处理被分配的分区消息,Consume需循环调用,应对rebalance
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| type consumerHandler struct{}
func (c consumerHandler) Setup(sarama.ConsumerGroupSession) error { return nil }
func (c consumerHandler) Cleanup(sarama.ConsumerGroupSession) error { return nil }
func (c consumerHandler) ConsumeClaim(session sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
for msg := range claim.Messages() {
session.MarkMessage(msg, "")
}
return nil
}
func runConsumerGroup(brokers []string, topic, groupID string) {
config := getConfig()
config.Consumer.Offsets.Initial = sarama.OffsetNewest
group, err := sarama.NewConsumerGroup(brokers, groupID, config)
if err != nil {
log.Fatalf("创建消费者组失败: %v", err)
}
defer group.Close()
fmt.Println("消费者启动成功,等待消息...")
handler := consumerHandler{}
for {
err := group.Consume(nil, []string{topic}, handler)
if err != nil {
log.Printf("消费异常: %v", err)
}
}
}
|
