RoseDB是一个基于bitcast存储模型的单机kv存储引擎,基于bitcast存储模型设计的kv存储引擎,所有的写操作都是先构建一个entry,经过编码后写到active logfile文件中,只有active logfile才能进行写操作,其他都为归档logfile日志文件,只能读,不能写。
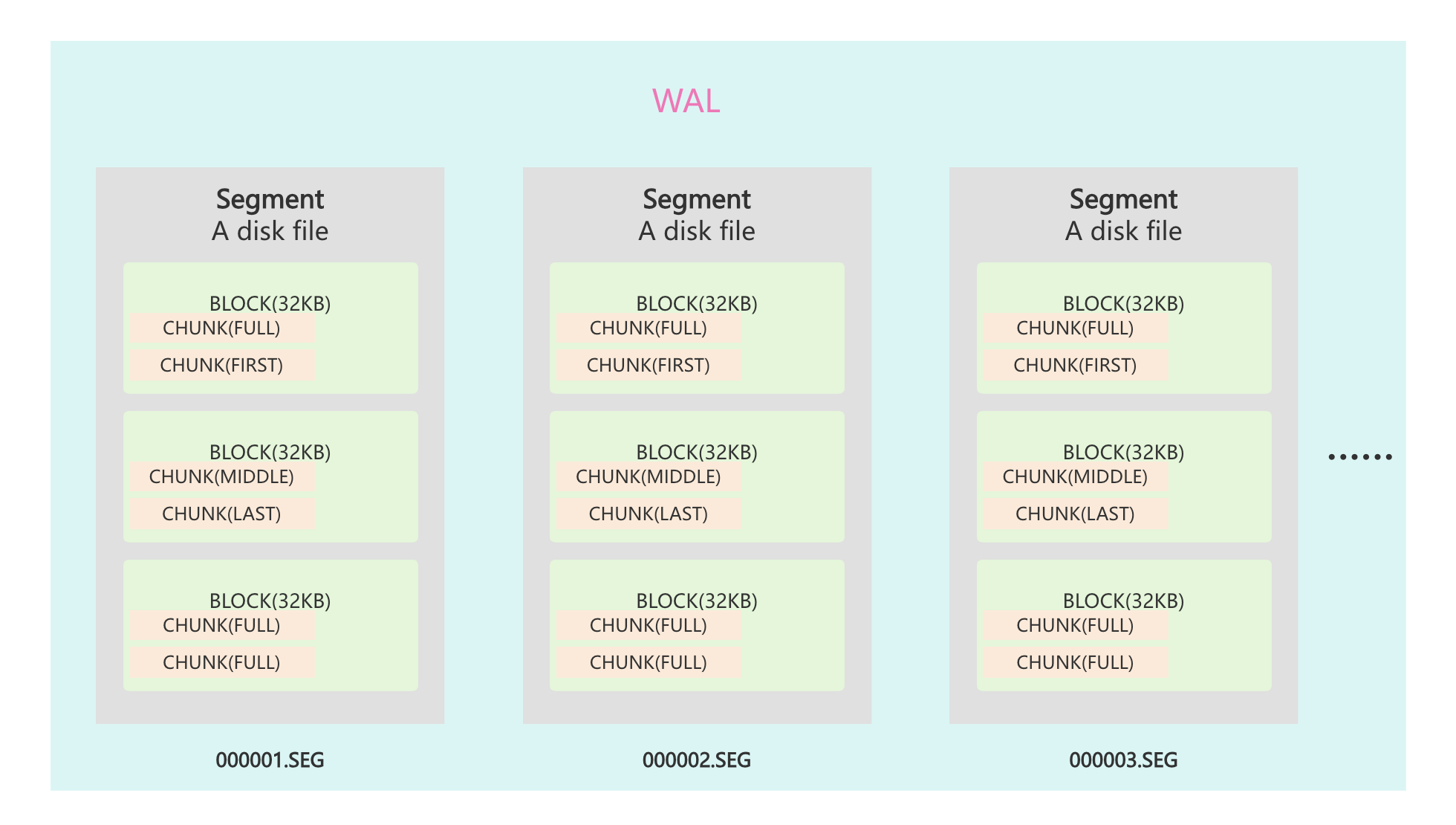
WAL WAL作为RoseDB的一个单独结构,实现了预写日志功能,一个WAL文件包含多个SEG段文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 type WAL struct { activeSegment *segment olderSegments map [SegmentID]*segment options Options mu sync.RWMutex bytesWrite uint32 renameIds []SegmentID pendingWrites [][]byte pendingSize int64 pendingWritesLock sync.Mutex closeC chan struct {} syncTicker *time.Ticker }
activeSegment:当前写入的段文件olderSegments:历史段,只能读pendingWrites:批量写入的缓冲
Segment Segment实现WAL的单段文件,负责在磁盘上以固定块(32KB)组织数据,提供chunk的写入、读取和校验
1 2 3 4 5 6 7 8 9 10 type segment struct { id SegmentID fd *os.File currentBlockNumber uint32 currentBlockSize uint32 closed bool header []byte startupBlock *startupBlock isStartupTraversal bool }
存储格式
块大小:32KB
Chunk头:7字节(4字节CRC,2字节Length,1字节Type)
当数据超过剩余空间时,会被拆成First,Middle,Last多个Chunk
数据写入 单条数据Write写入流程为:
检查当前数据是否超过段大小
若当前段已满,调用 rotateActiveSegment() 新建段
写入 activeSegment,返回 ChunkPosition
据 Sync / BytesPerSync 决定是否立刻 Sync
批量写入WriteAll
将 pendingWrites 一次性写入当前段
若 pendingSize 超过段大小,返回 ErrPendingSizeTooLarge
若当前段空间不足,先 rotate 再写
调用 segment.writeAll() 批量写入,最后清空 pendingWrites
数据读取 根据ChunkPosition进行查找,根据segmentId找到对应段,再按BlockNumber和ChunkOffset读取
1 2 3 4 5 6 7 8 9 type ChunkPosition struct { SegmentId SegmentID BlockNumber uint32 ChunkOffset int64 ChunkSize uint32 }
LogRecord 日志记录结构体,用于描述一条具体的数据操作,一条LogRecord对应一个chunk
1 2 3 4 5 6 7 type LogRecord struct { Key []byte Value []byte Type LogRecordType BatchId uint64 Expire int64 }
DB实例 DB 结构体是 RoseDB 实例的核心,封装了所有数据库运行时所需的关键组件和状态。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 type DB struct { dataFiles *wal.WAL hintFile *wal.WAL index index.Indexer options Options fileLock *flock.Flock mu sync.RWMutex closed bool mergeRunning uint32 batchPool sync.Pool recordPool sync.Pool encodeHeader []byte watchCh chan *Event watcher *Watcher expiredCursorKey []byte cronScheduler *cron.Cron }
dataFiles (*wal.WAL):
持久化存储所有键值数据的 Write-Ahead Log(WAL)对象。
所有的增删改数据操作都以追加写形式写入到该 WAL 里,实现高效崩溃恢复和持久性保障。
hintFile (*wal.WAL):
用于加速冷启动恢复索引的 hint 文件 WAL,仅存储 key 到 WAL 物理位置的有效映射关系。
在合并(Merge)时生成,重启时若存在则优先加载来快速构建索引。
index (index.Indexer):
内存中的键到数据物理位置(WAL 位置)的映射结构,实现秒级查找。
采用 B+ 树索引结构。
options (Options):RoseDB 的配置信息,包括数据目录、段大小、合并周期等。
fileLock (*flock.Flock): 用于防止同一目录多进程同时操作数据库的文件锁,对应磁盘 FLOCK 文件。
mergeRunning (uint32): 标记合并(Merge)操作的运行状态,防止并发重复触发合并。
batchPool (sync.Pool) :Batch 对象的对象池,用于高效复用批量写入操作的批次实例,降低 GC 压力。
recordPool (sync.Pool):LogRecord 对象的对象池,同理用于减少频繁创建和销毁带来的性能开销。
watchCh (chan *Event): 供用户消费变更事件的通道,支持变更订阅与通知。
watcher (*Watcher):配合 watchCh 实现事件分发和订阅的后台管理实体。
启动初始化 通过文件锁flock防止多个进程同时写WAL,启动时通过loadMergeFiles检查是否有临时合并目录,如果有则替换回主数据目录。调用wal.Open打开WAL数据文件,loadIndex重建内存索引,loadIndex包括两步:先读Hint文件进行快速装载,再通过WAL文件中加载并重建索引。(Hint是merge生成的索引快照,加载块,WAL再回放能把新写入补齐)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 func Open (options Options) error ) { if err := checkOptions(options); err != nil { return nil , err } if _, err := os.Stat(options.DirPath); err != nil { if err := os.MkdirAll(options.DirPath, os.ModePerm); err != nil { return nil , err } } fileLock := flock.New(filepath.Join(options.DirPath, fileLockName)) hold, err := fileLock.TryLock() if err = loadMergeFiles(options.DirPath); err != nil { return nil , err } if db.dataFiles, err = db.openWalFiles(); err != nil { return nil , err } if err = db.loadIndex(); err != nil { return nil , err } return db, nil }
写入流程 Rosedb的写入采用WAL追加写+内存索引更新,DB API最终都会走到Batch,核心提交逻辑在commit中。
批量操作管理 通过Batch结构体实现对数据库的批量原子写操作,将多条写操作聚合成一次持久化提交.
1 2 3 4 5 6 7 8 9 10 11 type Batch struct { db *DB pendingWrites []*LogRecord pendingWritesMap map [uint64 ][]int options BatchOptions mu sync.RWMutex committed bool rollbacked bool batchId *snowflake.Node buffers []*bytebufferpool.ByteBuffer }
日志记录操作
lookupPendingWrites:查询同批次是否有关于key的相关操作,用于put和get进行查询
appendPendingWrites:同批次添加日志记录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 func (b *Batch) byte ) *LogRecord { if len (b.pendingWritesMap) == 0 { return nil } hashKey := utils.MemHash(key) for _, entry := range b.pendingWritesMap[hashKey] { if bytes.Equal(b.pendingWrites[entry].Key, key) { return b.pendingWrites[entry] } } return nil } func (b *Batch) byte , record *LogRecord) { b.pendingWrites = append (b.pendingWrites, record) if b.pendingWritesMap == nil { b.pendingWritesMap = make (map [uint64 ][]int ) } hashKey := utils.MemHash(key) b.pendingWritesMap[hashKey] = append (b.pendingWritesMap[hashKey], len (b.pendingWrites)-1 ) }
Put 通过lookupPendingWrites检查同一批次是否已有记录,有则进行覆盖,没有就取一个LogRecord 放入 pendingWrites
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 func (b *Batch) byte ) error { b.mu.Lock() record := b.lookupPendingWrites(key) if record == nil { record = b.db.recordPool.Get().(*LogRecord) b.appendPendingWrites(key, record) } record.Key, record.Value = key, value record.Type, record.Expire = LogRecordNormal, 0 b.mu.Unlock() return nil }
Commit 使用雪花ID作为批次标识,将每条record编码后放入WAL的待写缓冲中,再追加一条提交完成记录表示结束提交。最后通过WriteALL把待写队列一次性刷进当前 WAL 段文件,并返回每条记录对应的磁盘位置(ChunkPosition)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 func (b *Batch) error { defer b.unlock() b.mu.Lock() defer b.mu.Unlock() batchId := b.batchId.Generate() now := time.Now().UnixNano() for _, record := range b.pendingWrites { buf := bytebufferpool.Get() b.buffers = append (b.buffers, buf) record.BatchId = uint64 (batchId) encRecord := encodeLogRecord(record, b.db.encodeHeader, buf) b.db.dataFiles.PendingWrites(encRecord) } buf := bytebufferpool.Get() b.buffers = append (b.buffers, buf) endRecord := encodeLogRecord(&LogRecord{ Key: batchId.Bytes(), Type: LogRecordBatchFinished, }, b.db.encodeHeader, buf) b.db.dataFiles.PendingWrites(endRecord) chunkPositions, err := b.db.dataFiles.WriteAll() if err != nil { b.db.dataFiles.ClearPendingWrites() return err } if len (chunkPositions) != len (b.pendingWrites)+1 { panic ("chunk positions length is not equal to pending writes length" ) } b.committed = true return nil }
索引更新 索引以Btree作为数据结构,WAL成功构更新内存BTree,索引记录key到
1 2 3 4 5 6 7 8 9 for i, record := range b.pendingWrites { if record.Type == LogRecordDeleted || record.IsExpired(now) { b.db.index.Delete(record.Key) } else { b.db.index.Put(record.Key, chunkPositions[i]) } b.db.recordPool.Put(record) }
读取过程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 func (b *Batch) byte ) ([]byte , error ) { now := time.Now().UnixNano() b.mu.RLock() record := b.lookupPendingWrites(key) b.mu.RUnlock() if record != nil { if record.Type == LogRecordDeleted || record.IsExpired(now) { return nil , ErrKeyNotFound } return record.Value, nil } chunkPosition := b.db.index.Get(key) if chunkPosition == nil { return nil , ErrKeyNotFound } chunk, err := b.db.dataFiles.Read(chunkPosition) if err != nil { return nil , err } record = decodeLogRecord(chunk) if record.Type == LogRecordDeleted { panic ("Deleted data cannot exist in the index" ) } if record.IsExpired(now) { b.db.index.Delete(record.Key) return nil , ErrKeyNotFound } return record.Value, nil }
先查 batch 内 pendingWrites(同批次读自己写)
未命中则查内存索引 index.Get(key)。
根据 ChunkPosition 从 WAL 读 chunk。
decodeLogRecord 后检查是否 deleted/expired。过期数据会触发索引删除并返回 ErrKeyNotFound。
Merge合并 使用 bitcask 模型实现的 kv 存储引擎不会直接原理删除数据,而是通过 compaction gc 合并垃圾回收的方式来释放空间。Merge本质是Bitcask中的日志压缩(Compaction),把旧段文件中有效的最新记录重写到新文件,丢弃无效历史(覆盖旧值,删除标记),并生成HINT加速重启索引恢复。
1 2 3 4 5 6 7 8 9 10 11 12 13 func (db *DB) bool ) error { if err := db.doMerge(); err != nil { return err } if !reopenAfterDone { return nil } db.mu.Lock() defer db.mu.Unlock() }
doMerge
记录当前Active segment id,然后打开新segment 文件,使新写入不阻塞进入新段
打开临时mergeDB,并打开单独HINT文件
判断记录是否有效
记录类型必须是LogRecordNormal类型,且未过期
当前索引位置与旧文件中位置一致
将有效记录写入mergeDB,同时写入Hint文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 func (db *DB) error { atomic.StoreUint32(&db.mergeRunning, 1 ) defer atomic.StoreUint32(&db.mergeRunning, 0 ) prevActiveSegId := db.dataFiles.ActiveSegmentID() if err := db.dataFiles.OpenNewActiveSegment(); err != nil { db.mu.Unlock() return err } mergeDB, err := db.openMergeDB() defer func () _ = mergeDB.Close() }() buf := bytebufferpool.Get() now := time.Now().UnixNano() defer bytebufferpool.Put(buf) reader := db.dataFiles.NewReaderWithMax(prevActiveSegId) for { buf.Reset() chunk, position, err := reader.Next() if err != nil { if err == io.EOF { break } return err } record := decodeLogRecord(chunk) if record.Type == LogRecordNormal && (record.Expire == 0 || record.Expire > now) { db.mu.RLock() indexPos := db.index.Get(record.Key) db.mu.RUnlock() if indexPos != nil && positionEquals(indexPos, position) { record.BatchId = mergeFinishedBatchID newPosition, err := mergeDB.dataFiles.Write(encodeLogRecord(record, mergeDB.encodeHeader, buf)) if err != nil { return err } _, err = mergeDB.hintFile.Write(encodeHintRecord(record.Key, newPosition)) if err != nil { return err } } } } }
将记录写入到新文件后,需要在merge文件中记录参与merge文件的最大ID, 供后续替换文件和重建索引使用
1 2 3 4 5 6 7 8 9 10 mergeFinFile, err := mergeDB.openMergeFinishedFile() if err != nil { return err } _, err = mergeFinFile.Write(encodeMergeFinRecord(prevActiveSegId)) if err != nil { return err } return nil
loadMergeFiles
获取标识合并完成的最大段号
将1~mergeFinSegmentId的主目录旧段删除,并用merge目录对应段替换
清理-merge临时目录
在替换期间,所有读请求都会阻塞
loadIndex 合并后key位置可能发生变化,此时需要重建索引