单线程模型
Redis 的 “单线程” 并非指服务器进程仅含一个线程,而是核心的命令执行逻辑由单个线程串行处理。多线程模型虽然在某些方面表现优异,但是它却引入了程序执行顺序的不确定性,带来了并发读写的一系列问题,增加了系统复杂度、同时可能存在线程切换、甚至加锁解锁、死锁造成的性能损耗。
Redis 服务器进程包含多个线程,核心逻辑与辅助操作完全分离:
- 核心线程(主线程):负责处理客户端命令请求(如get/set)、执行数据读写操作、解析命令语法 —— 这是 Redis “单线程模型”的核心载体,所有命令执行严格串行,不存在并发竞争。
- 辅助线程:负责耗时的非核心操作,不参与命令执行,例如:
- 网络 IO 相关线程:处理 TCP 连接建立、数据接收与发送的底层 IO 操作(部分版本引入)
- 后台线程:执行 AOF 日志重写、RDB 持久化、大 Key 删除等耗时任务,避免阻塞主线程;
- 集群相关线程:处理节点心跳检测、数据同步等集群维护操作。、
IO多路复用
单线程的天然局限是 “无法同时处理多个 IO 请求”—— 若一个客户端连接占用线程等待数据,其他客户端会被阻塞。而 Redis 通过IO 多路复用机制,让单线程可同时管理数万甚至数十万客户端连接。
IO 多路复用的核心思想是:由一个线程/进程监听多个 socket(客户端连接)的 IO 事件(可读 / 可写),当某个 socket 的事件就绪时(如客户端发送数据),内核通知应用程序处理,处理完成后继续监听其他 socket。一个Socket在内核对应一个fd,避免为每一个Socket创建线程
Redis通过封装AE事件处理器模块,根据操作系统自动选择最优的多路复用实现,
单线程工作流程
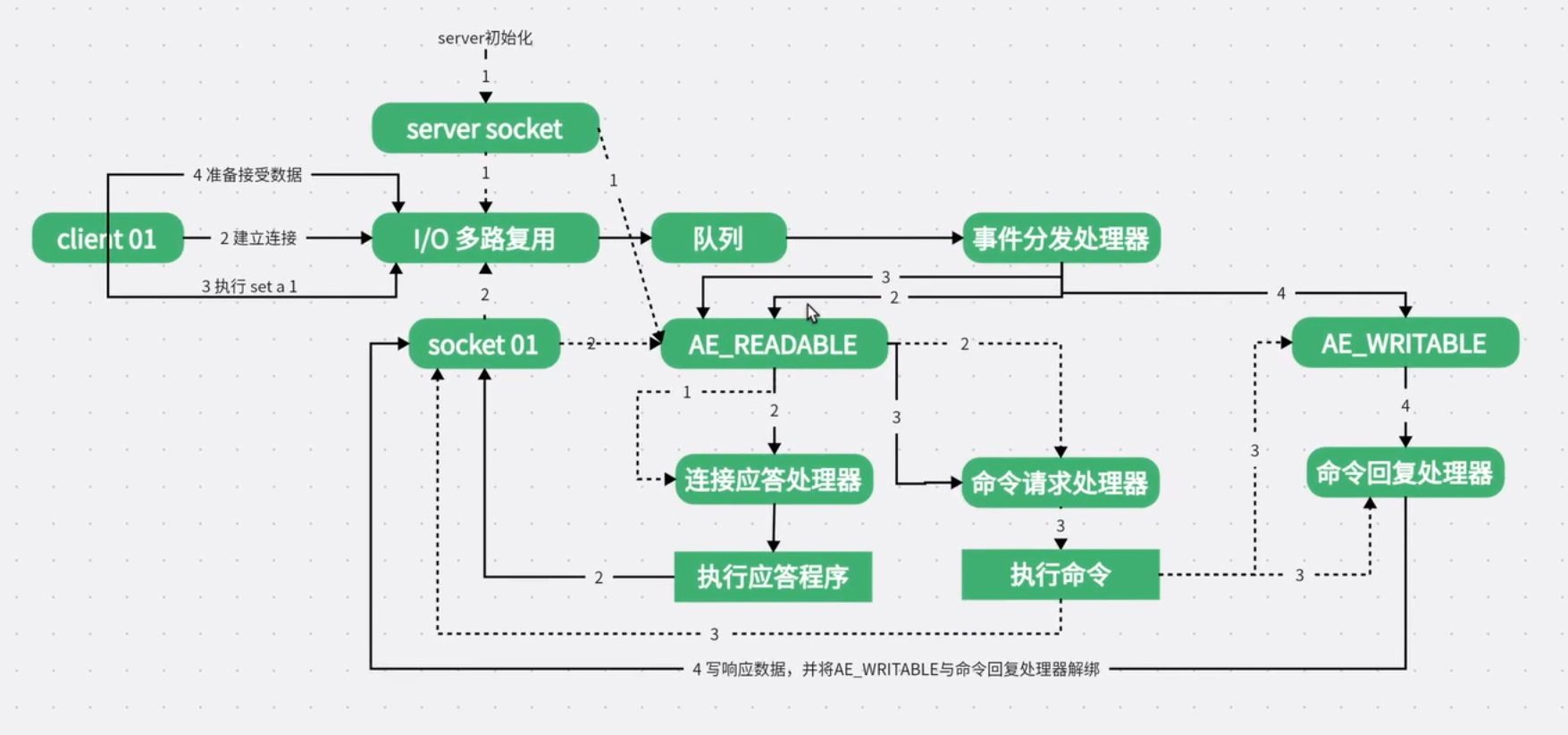
- Server Socket:监听端口的主Socket,用于接收新连接
- I/O多路复用:监听各个Socket的可读/可写状态,redis使用epoll多路复用API
- Socket01:客户端连接建立后建立的通信Socket
- 队列:事件队列,存放就绪的I/O事件
AE_READABLE:表示Socket可读(有数据到达)AE_WRITABLE:表示Socket可写(可以发送响应)
Redis 启动时创建一个 server socket,绑定到指定端口,使用listen()监听该端口,等待客户端连接,I/O 多路复用 模块开始工作,监控 server socket 是否可读(即是否有新连接)。
客户端 client 01 发起 TCP 连接请求,server socket 接收到连接请求,触发 AE_READABLE 事件,I/O 多路复用 检测到 server socket 可读,将事件放入 **队列,**事件分发处理器 从队列取出事件,调用 **连接应答处理器,**连接应答处理器 调用 accept() 创建新的 socket 01,新的 socket 01 被注册到 I/O 多路复用,监听其 AE_READABLE 事件。
客户端发送命令 set a 1 到 socket 01,数据到达 socket 01,触发AE_READABLE事件,I/O 多路复用 检测到 socket 01 可读,将事件放入 **队列,**事件分发处理器 从队列取出事件,调用 **命令请求处理器,**命令请求处理器 从 socket 01 读取数据,解析成命令(如 SET a 1),调用 执行命令 模块,实际执行 Redis 内部逻辑(如更新内存数据)
命令执行完成后,生成响应,命令回复处理器 将响应数据准备好,并设置 socket 01 为 AE_WRITABLE(可写),I/O 多路复用 检测到socket 01可写,触发 AE_WRITABLE 事件
事件进入队列,事件分发处理器 调用 **命令回复处理器,**命令回复处理器 触发 **执行应答程序,**执行应答程序 调用 write() 将响应数据写入 socket 01,写完后,解除 AE_WRITABLE 事件绑定(避免重复触发)
I/O多路复用的本质:事件通知机制
用户空间:一个线程调用epoll_wait(),阻塞等待
内核空间:监控多个文件描述符(fd),当任一fd就绪,唤醒该线程
多线程模型
redis多线程只用在了IO读写方面,redis命令执行还是单线程的。Redis的主要性能瓶颈是内存或网络带宽而并非CPU,为解决网络IO问题引入多线程模型。
大key删除问题: 正常情况下使用 del 指令可以很快的删除数据,而当被删除的 key 是一个非常大的对象时,例如包含了成千上万个元素的 hash 集合时,那么 del 指令就会造成 Redis 主线程卡顿。
通过惰性删除有效避免Redis卡顿问题(大key删除等问题):先将key从数据库字典中解绑,将删除工作交给后台异步子线程完成。
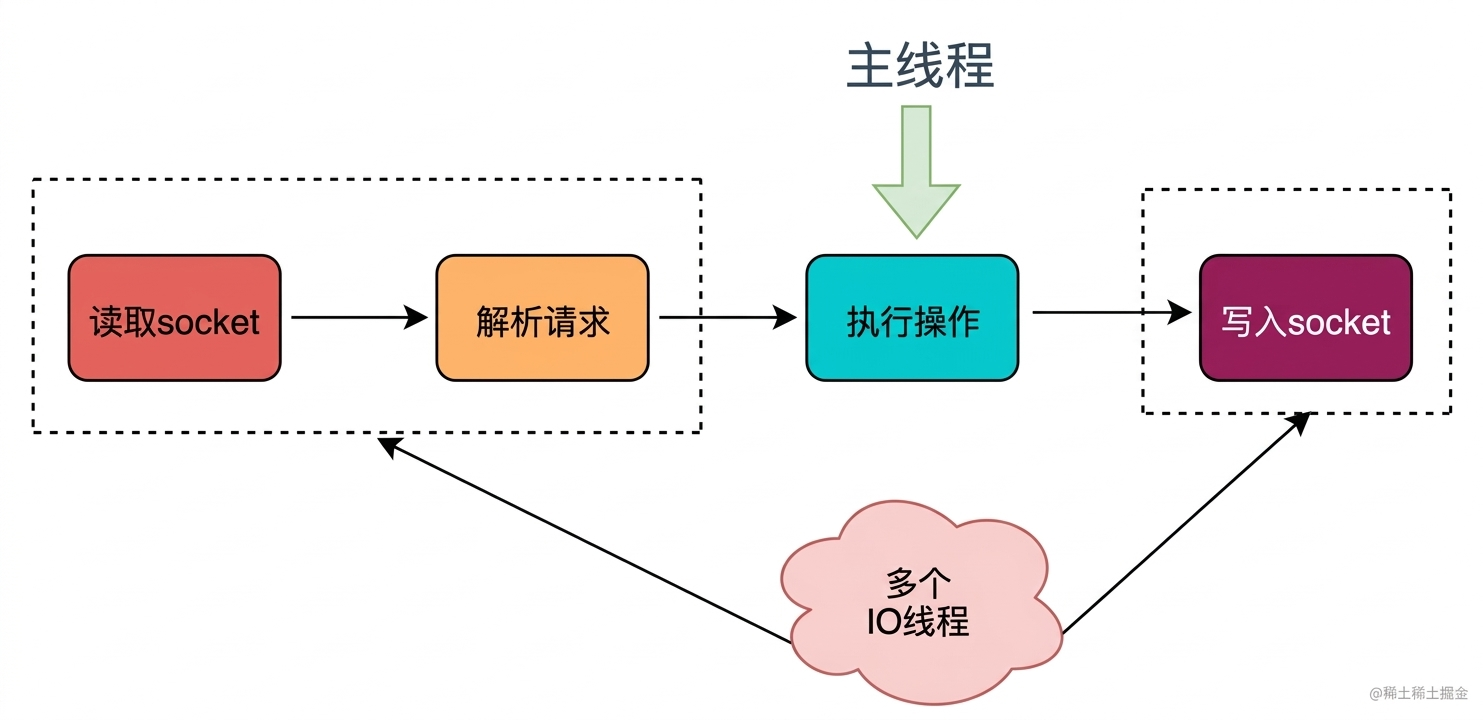
I/O 的读和写本身是堵塞的,比如当 socket 中有数据时,Redis 会通过调用先将数据从内核态空间拷贝到用户态空间,再交给 Redis 调用,而这个拷贝的过程就是阻塞的,当数据量越大时拷贝所需要的时间就越多,而这些操作都是基于单线程完成的。
主要实现思路是将主线程的 IO 读写任务拆分给一组独立的线程去执行,这样就可以使多个 socket 的读写可以并行化了,采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗),将最耗时的Socket的读取、请求解析、写入单独外包出去,剩下的命令执行仍然由主线程串行执行并和内存的数据交互。
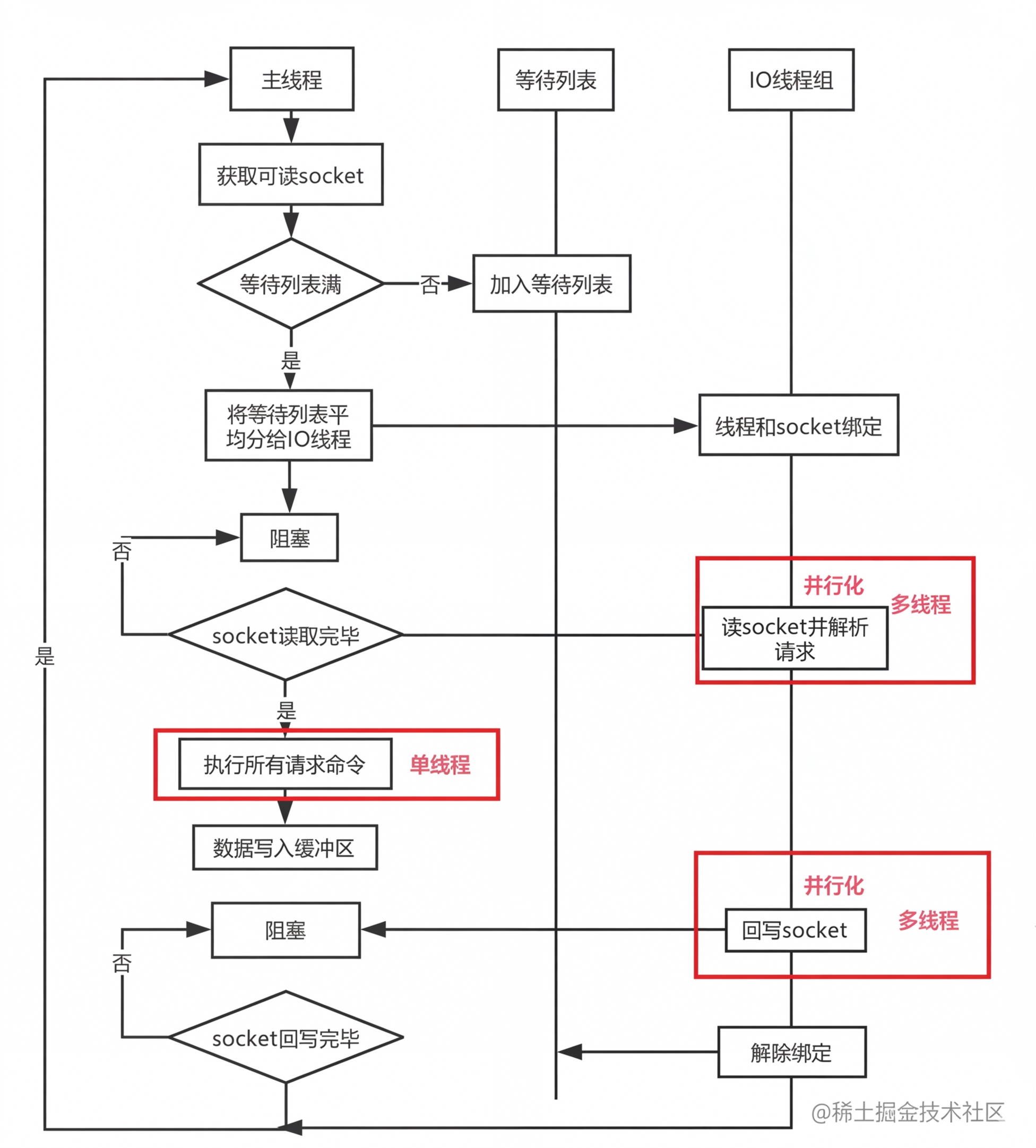
多线程执行流程:
主线程获取 socket 放入等待列表
将 socket 分配给各个 IO 线程(并不会等列表满)
主线程**阻塞等待 IO 线程(多线程)**读取 socket 完毕
主线程执行命令 - 单线程(如果命令没有接收完毕,会等 IO 下次继续)
主线程阻塞等待 IO 线程(多线程)将数据回写 socket 完毕(一次没写完,会等下次再写)
主从复制
为了避免单点故障,通常的做法是将数据库复制多个副本以部署在不同的服务器上,这样即使有一台服务器出现故障,其他服务器依然可以继续提供服务。当一台数据库中的数据更新后,自动将更新的数据同步到其他数据库上。
数据库分为两类,一类主数据库master,一类从数据库slave。主数据库可以进行读写操作,当写操做导致数据变化时自动将数据同步给从数据库,而从数据库一般是只读的,并接收主数据库同步过来的数据。一个主数据库可以拥有多个从数据库,而一个从数据库只能拥有一个主数据库。
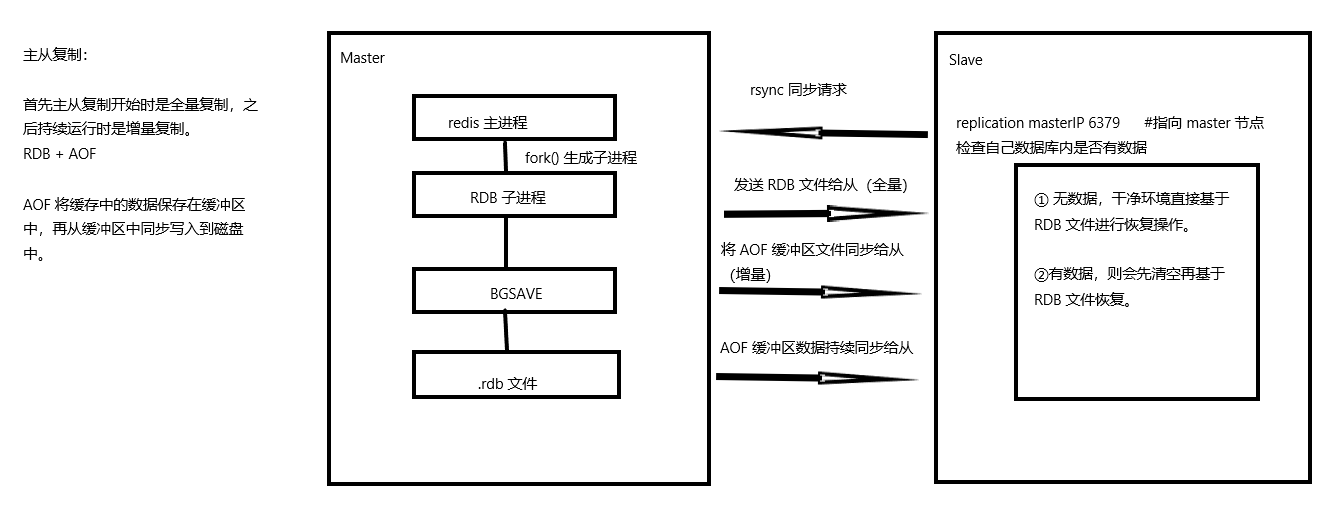
全量复制:
- 从服务器发送SYNC命令,请求开始同步
- 主服务器生成RDB快照,将生成的RDB快照发送给从服务器
- 从服务器接收RDB文件后,会清空当前数据集,并载入RDB文件中的数据
- 在RDB文件生成和传输期间,主服务器会记录所有接收到的写命令,写入到
replication backlog buffer - 将
replication backlog buffer中的写命令发送给从服务器保证数据的一致性
增量复制:
增量同步允许从服务器从断点处继续同步,而不是每次都进行完全同步。
主服务器如何知道将哪些增量数据发送给从服务器?
repl_backlog_buffer:是一个环形缓冲区,用于主从服务器断连后,从中找到差异的数据Replication offset:标记上面那个缓冲区的同步进度,主从服务器都有各自的偏移量,主服务器使用master_repl_offset来记录自己写到的位置,从服务器使用slave_repl_offset来记录自己读到的位置。
在主服务器进行命令传播时,不仅会将写命令发送给从服务器,还会将写命令写入到repl_backlog_buffer缓冲区中,因此这个缓冲区里会保存最近传播的写命令
网络断开后,当从服务器重新连接上主服务器时,从服务器会通过psync命令将自己的复制偏移量slave_repl_offset发送给主服务器,主服务器根据自己的master_repl_offset和slave_repl_offset之间的差距,来决定对从服务器执行哪种同步操作:
- 如果判断出从服务器要读取的数据还在
repl_backlog_buffer缓冲区里,那么主服务器将采用增量同步的方式; - 相反,如果判断出从服务器要读取的数据已经不存在
repl_backlog_buffer缓冲区里,那么主服务器将采用全量同步的方式。
哨兵模式
哨兵的出现主要是解决了主从复制出现故障时需要人为干预的问题、
主要功能
- 集群监控:负责监控 redismaster 和 slave 进程是否正常工作
- 消息通知:如果某个 redis 实例有故障,那么哨兵负责发送消息作为报警通知给管理员
- 故障转移:如果 master node 挂掉了,会自动转移到 slave node 上
- 配置中心:如果故障转移发生了,通知 client 客户端新的 master 地址
原理
- 主节点的信息配置在哨兵 sentinel 的配置文件中。
- 哨兵节点会和配置的主节点建立起两条连接命令连接和订阅连接
- 哨兵会通过命令连接每 10s 发送一次 INFO 命令,通过 INFO 命令,主节点会返回自己的 run_id 和自己的从节点信息。
- 哨兵会对这些从节点也建立两条连接命令连接和订阅连接。
- 哨兵通过命令连接向从节点发送 INFO 命令,获取到他的一些信息(偏移量等)
- 哨兵节点会对redis指定频道发送对主节点信息的判断以及自身节点信息,其他哨兵节点也会订阅该频道
- 哨兵之间建立连接完成心跳检测。
故障转移
- 主节点故障,从节点同步连接中断,主从复制停止。
- 哨兵节点通过定期监控发现主节点出现故障。哨兵节点与其他哨兵节点进行协商,达成多数认同主节点故障的共识(客观下线)。这步主要是防止该情况:出故障的不是主节点,而是发现故障的哨兵节点或者是因为网络问题,该情况经常发生于哨兵节点的网络被孤立的场景下。
- 哨兵节点之间使用Raft算法选举出一个领导角色,由该节点负责后续的故障转移工作。
- 哨兵领导者开始执行故障转移:从节点中选择一个作为新主节点,让其他从节点同步新主节点。该工作也就是前面我们说到的人工操作恢复故障的工作。
- 哨兵节点会自动的通知客户端程序告知新的主节点是谁,并且后续客户端再进行写操作,就会针对新的主节点进行操作了。
集群模式
redis 的哨兵模式基本已经可以实现高可用、读写分离,但是在这种模式每台 redis 服务器都存储相同的数据,很浪费内存资源,所以在 redis3.0 上加入了 Cluster 群集模式,实现了 redis 的分布式存储,也就是每台 redis 节点存储着不同的内容。
数据分片
- Redis集群采用的算法是哈希槽分区算法。Redis集群中有16384个哈希槽(槽的范围是 0 -16383),将不同的哈希槽分布在不同的Redis节点上面进行管理,也就是每个Redis节点只负责一部分的哈希槽。在对数据进行操作的时候,集群会对使用CRC16算法对key进行计算并对16384取模(slot = CRC16(key)%16383),得到的结果就是 Key-Value 所放入的槽,通过这个值,去找到对应的槽所对应的Redis节点,然后直接到这个对应的节点上进行存取操作。
- 默认情况下,redis集群的读和写都是到master上去执行的,不支持slave节点读和写,因为Redis的读写分离,是为了横向任意扩展slave节点去支撑更大的读吞吐量。而redis集群架构下,本身master就是可以任意扩展的,如果想要支撑更大的读或写的吞吐量,都可以直接对master进行横向扩展。且从节点虽然有数据副本,但是不会参与slot路由决策
优点:可以方便的添加或者移除节点,并且无论是添加删除或者修改某一个节点,都不会造成集群不可用的状态。
Hash tag
集群模式中用于控制 key 分片(sharding)行为的一种特殊语法机制。确保多个相关的 key 被分配到同一个 hash slot(哈希槽),从而落在同一个 Redis 节点上。
因为集群不允许跨节点执行多key命令,所以通过在key中使用{}包裹一部分字符串,redis只对{}中的内容计算hash slot。
节点通信
不同的节点之间采用gossip协议进行通信,节点之间通讯的目的是为了维护节点之间的元数据信息。这些元数据就是每个节点包含哪些数据,是否出现故障,通过gossip协议,达到最终数据的一致性。
gossip协议常见的消息类型包含: ping、pong、meet、fail等等。
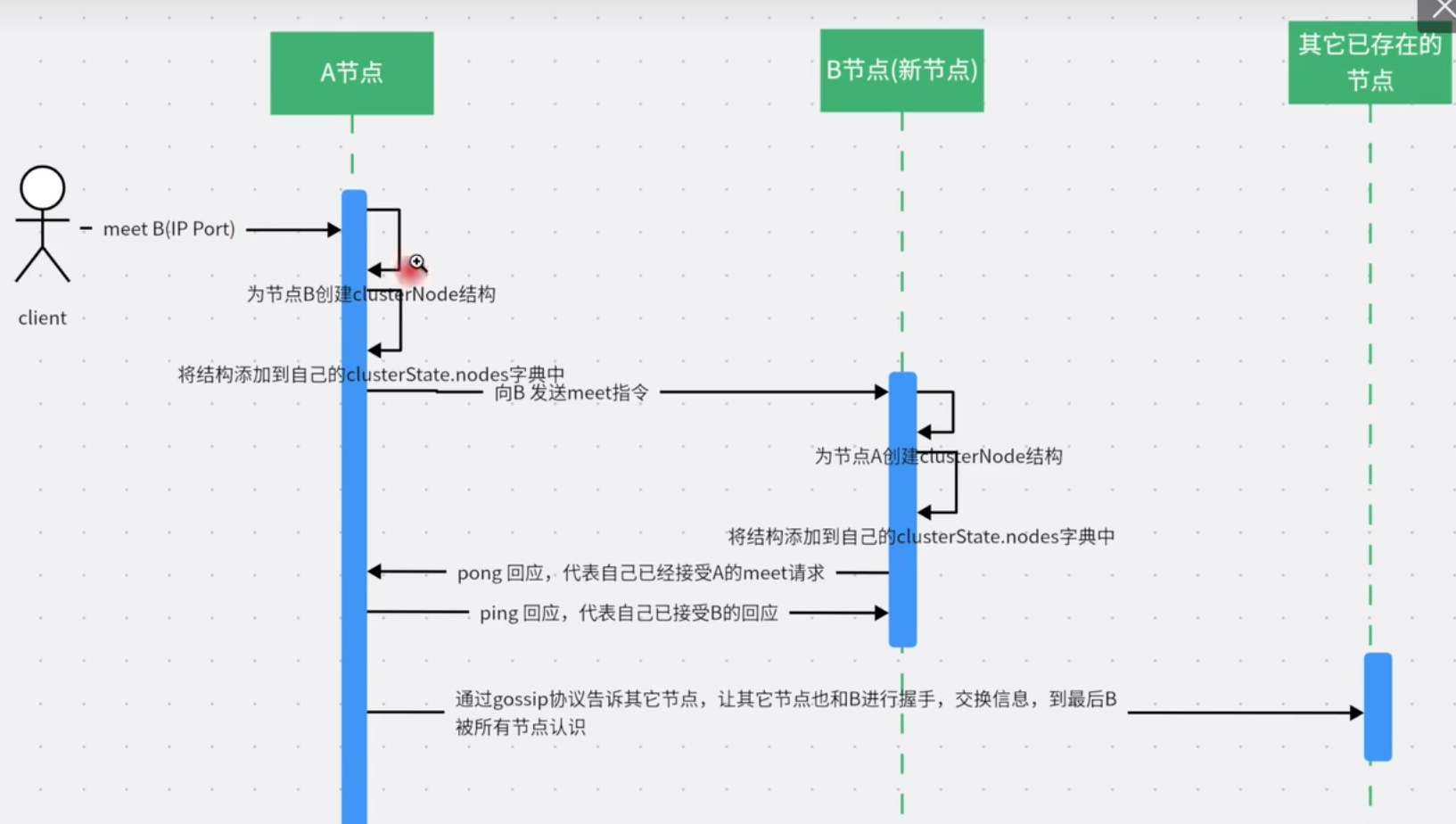
- meet:主要用于通知新节点加入到集群中,通过「cluster meet ip port」命令,已有集群的节点会向新的节点发送邀请,加入现有集群。
- ping:用于交换节点的元数据。每个节点每秒会向集群中其他节点发送 ping 消息,消息中封装了自身节点状态还有其他部分节点的状态数据,也包括自身所管理的槽信息等等。
- pong:ping和meet消息的响应,同样包含了自身节点的状态和集群元数据信息。
- fail:某个节点判断另一个节点 fail 之后,向集群所有节点广播该节点挂掉的消息,其他节点收到消息后标记已下线。
因为发送ping命令时要携带一些元数据,如果很频繁,可能会加重网络负担。因此,一般每个节点每秒会执行 10 次 ping,每次会选择 5 个最久没有通信的其它节点。
如果发现某个节点通信延时达到了 cluster_node_timeout / 2,那么立即发送 ping,避免数据交换延时过长导致信息严重滞后。比如说,两个节点之间都 10 分钟没有交换数据了,那么整个集群处于严重的元数据不一致的情况,就会有问题。所以 cluster_node_timeout 可以调节,如果调得比较大,那么会降低 ping 的频率。
每次 ping,会带上自己节点的信息,还有就是带上 1/10 其它节点的信息,发送出去,进行交换。至少包含 3 个其它节点的信息,最多包含 (总节点数 - 2)个其它节点的信息。
集群请求
Redis集群采用去中心化的思想,没有中心节点,当客户端操作的key没有分配到该node上时,Redis会返回转向指令,指向正确的node。请求重定向到其他节点中获取。
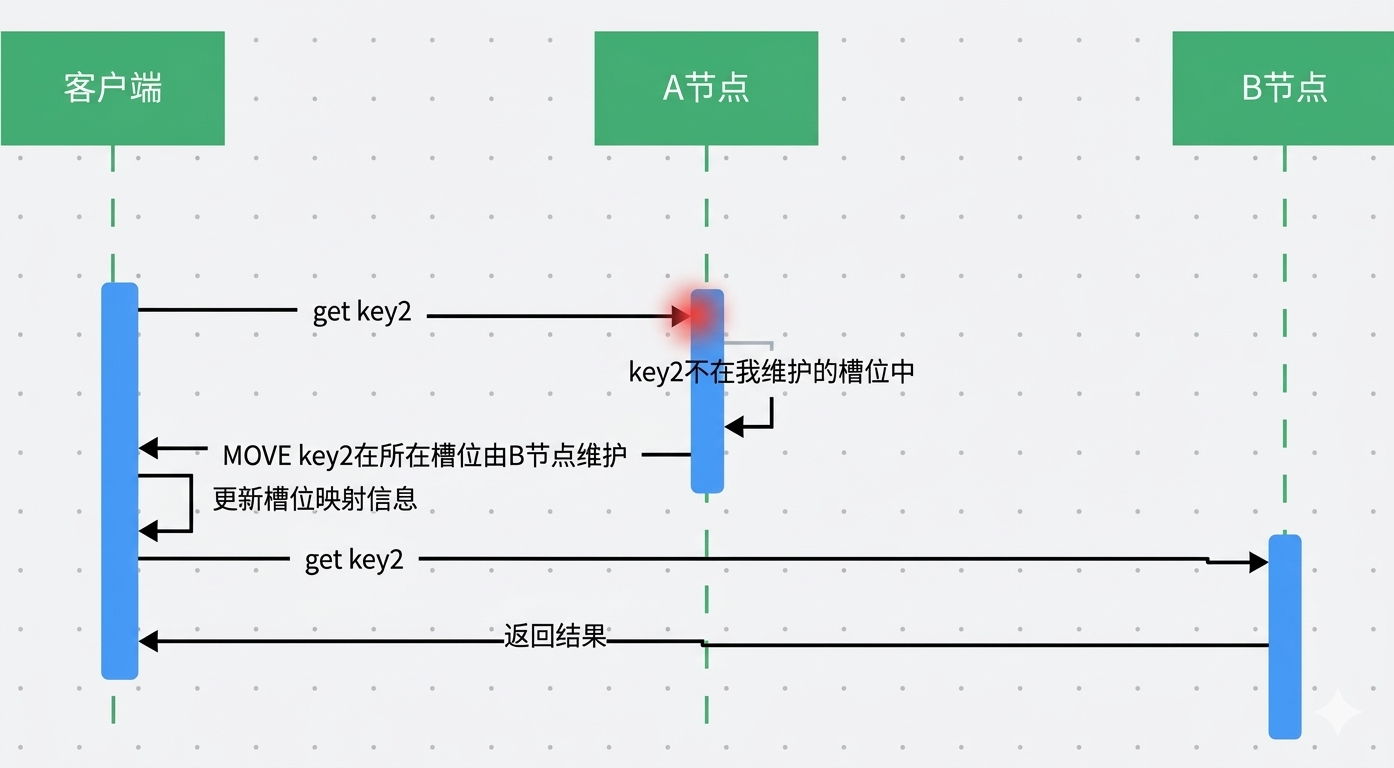
重定向过程显然会增加集群的网络负担和单次请求耗时。所以大部分的客户端都是smart的。所谓 smart客户端,就是指客户端本地维护一份hashslot => node的映射表缓存,大部分情况下,直接走本地缓存就可以找到hashslot => node,不需要通过节点进行moved重定向
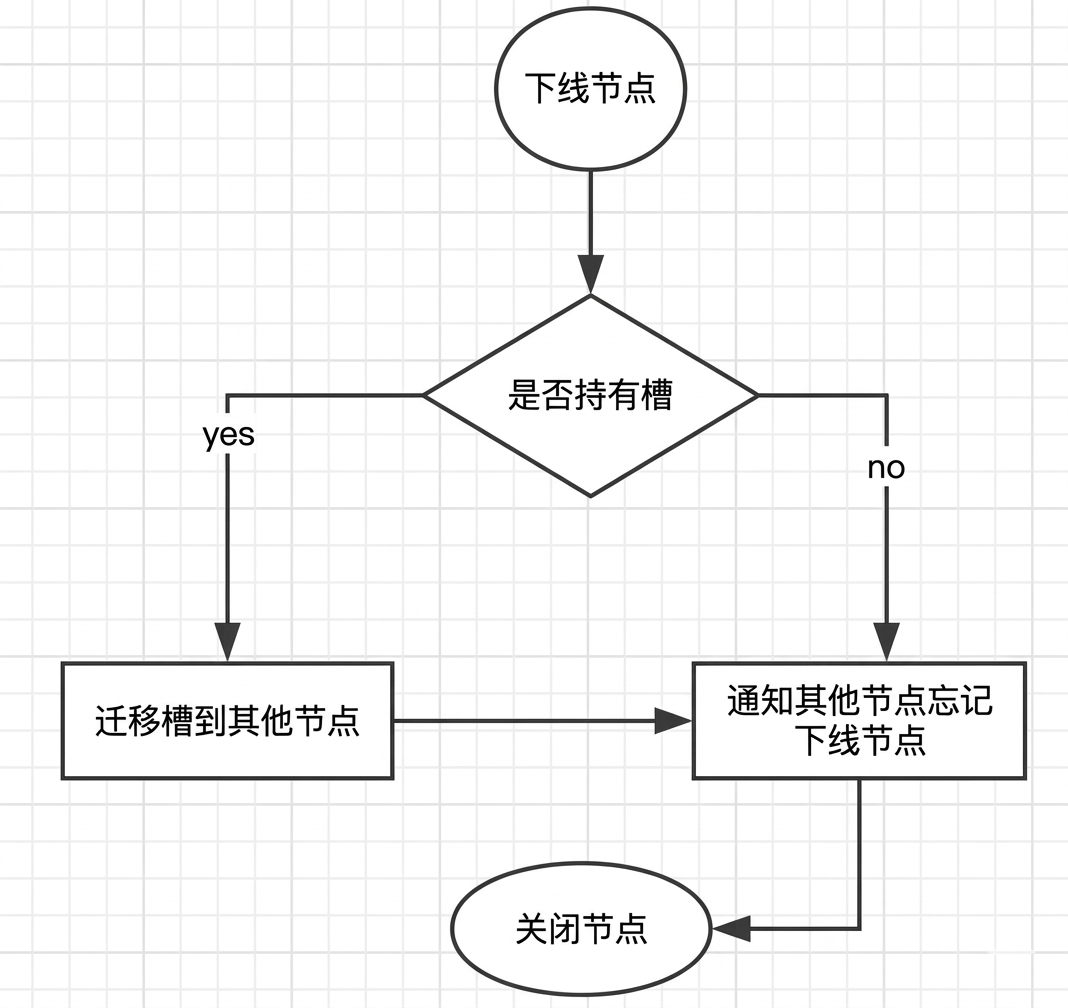
集群收缩与扩容
由于每个节点中保存着槽数据,因此当缓存节点数出现变动时,这些槽数据会根据对应的虚拟槽算法被迁移到其他的缓存节点上。
- 扩容:添加新节点后,需要将一些槽和数据从旧节点迁移到新节点
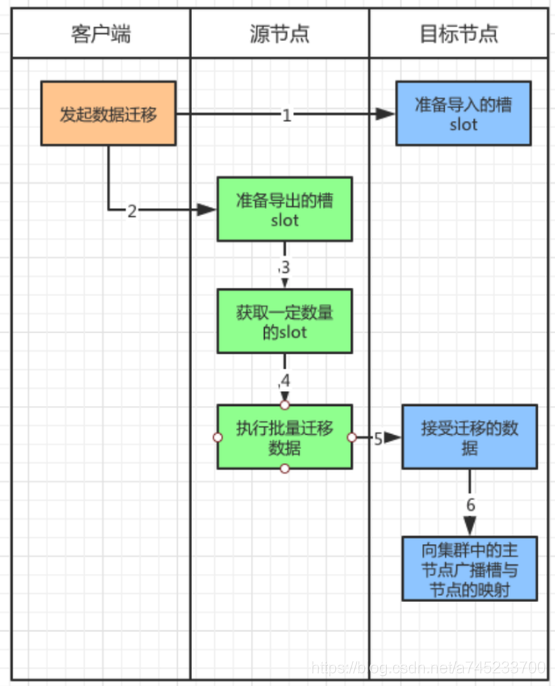
- 收缩:迁移槽,通过命令
cluster forget {downNodeId}通知其他的节点。
为了安全删除节点,Redis集群只能下线没有负责槽的节点。因此如果要下线有负责槽的master节点,则需要先将它负责的槽迁移到其他节点。迁移的过程也与上线操作类似,不同的是下线的时候需要通知全网的其他节点忘记自己,此时通过命令 cluster forget {downNodeId} 通知其他的节点。